Data processing is crucial to organizations, but outdated, expensive, and slow tools can hinder operational effectiveness. For many organizations, SQL and relational databases have been the go-to tool for data processing. While SQL is efficient for handling small to medium-sized datasets and simple queries, it often remains the default solution as an organization's datasets and queries grow in complexity. As datasets become larger and more complex, traditional data storage tools like start to show their limitations. This article highlights the limitations of SQL and traditional RDBMS's for data storage and processing and explores a more powerful and flexible solution.
In the field, we've observed organizations use SQL databases to perform complex data analysis with queries resembling complex algorithms over simple joins or merges; we've seen organizations using separate databases to store raw and cleaned data; we've seen organizations with schema drift, something SQL is hypothetically supposed to solve. Organizations often think they can or should use SQL to process their data because that's what they already know, and it can transform data. SQL is a powerful tool, but not for every use case.
SQL has many limitations for the modern application. Limited scalability, flexibility, and support for non-tabular data, along with a lack of distributed processing capability limit its usefulness. SQL is good at only a small subset of data activities - storing pre-defined, relational columnar information and doing some light manipulation. In summary, it is good at what it is designed to do.
SQL databases are designed to scale vertically, but adding more resources to the same server doesn't work ad infinitum. It doesn't help when it crashes. With larger and larger volumes of data, SQL also falls over when performing even simple queries. Finally, as business logic necessarily changes, SQL databases cannot keep up. They just are not designed to do so.
As the list of applications for a business's data expand, organizations first turn to leveraging existing datasets. Problems inevitably arise when use cases outgrow or out-scope SQL databases. What starts as simple queries turns into complicated joins, nested queries, niche filtering and conditional logic. These operations just aren't well suited for SQL from a processing point of view, or from a human understanding point of view. The query, which has become a set of independent functions, fades into obscurity becoming unreadable, hard to debug, and frustrating to work with.
Then there is the problem of what to do with data that isn't neatly tabular. Text, image, audio - any kind of business information that cannot be stored in a table - will not work in a SQL database. Not only is it impossible to process this data with SQL, it's not even possible to store it.
Lastly there are the fiscal and temporal costs of using a SQL database to store and process data. Licensing fees associated with SQL DBMS's, cost of scaling on-premise hardware and constant maintenance (and salaries of those maintainers) can constitute an egregious cost for an organization attempting to push data through SQL. There is an additional temporal cost spent in designing a rigid SQL database schema to accommodate current and future business logic. Time is spent creating and optimizing queries. And finally there is time spent waiting for those queries to run - sometimes days, sometimes weeks, and sometimes long enough for the engineer to get suspicious and shut it down with no value from associated run costs.
What, then, is a better alternative for processing data? Data processing can be broken down into two primary components: storage and compute. The most cost effective way to store data is binary large object (blob). Paired with modern compute tools designed to process data, not only is data manipulation easier and clearer to the human, but it's also also processed quickly and cost-effectively.
| SQL Databases | Blob Storage & Distributed Compute | |
| Scalability | Limited vertical scalability prevents effective error handling and adaptability. | Highly scalable, can handle large amounts of data with ease, resources can be added or removed as needed. |
| Flexibility | Rigid schema requires predefined data structures. | Schema-less and adaptable to changing business requirements. |
| Data Types | Primarily structured, tabular data. | Both structured and unstructured data, including images, videos, and log files. |
| Processing Capabilities | Suitable for simple queries and joins but struggles with complex data manipulation tasks. | Designed for parallel processing, efficiently handles complex data manipulation tasks. |
| Cost Effectiveness | Licensing fees, expensive hardware, and maintenance costs. | Pay-as-you-go storage, cost-effective compute resources, reduced maintenance costs. |
| Ease of Implementation | Familiar technology but requires extensive planning and schema design. | May require learning new tools and technologies but offers more flexibility and adaptability. |
Storing data in blob format offers several benefits, including cost-effectiveness and seamless integration with big data processing tools. Blob storage is designed to handle large amounts of unstructured data, such as images, videos, and log files, which are becoming increasingly common in modern organizations. The cost of storage this way is relatively low compared to other storage options, as users only pay for the storage they use, and can easily scale their storage capacity up or down as needed. Additionally, blob storage integrates well with big data processing tools like Hadoop, Spark, and Hive, allowing users to store and process large datasets efficiently. Its flexibility and scalability make it an excellent choice for businesses looking to store and process large amounts of data cost-effectively.
Using distributed or parallelized compute offers several benefits for processing data. These tools are designed to process vast amounts of data by breaking it down into smaller chunks and processing them in parallel, which can significantly improve processing times. By distributing processing tasks across multiple nodes or servers, these tools can handle larger workloads without putting a strain on individual resources. Additionally, these tools offer fault tolerance and can automatically recover from node failures, ensuring that processing tasks are completed without interruption. This parallelized processing capability also allows for greater flexibility in data processing, as users can choose the level of parallelism required based on the size of the dataset and available resources. Ultimately, using distributed or parallelized compute can provide businesses with the ability to process large datasets faster and more efficiently, making it an attractive option for data processing tasks.
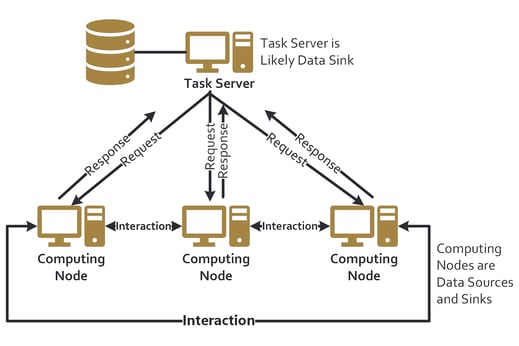
To be sure, it is always important to choose the right tools for the job. There are plenty of use cases where SQL databases will continue to shine. However, when it comes to processing large datasets, distributed computing systems and blob storage offer a powerful and efficient solution. Data, it must be understood, is a multifaceted discipline. Partnering with StandardData can provide businesses with the expertise and resources they need to efficiently manage, process, and analyze their data, making informed decisions that can drive growth and success.